
技術者KのPython道場 番外編1.データ解析の精度向上
こんにちは、技術者Kです。
前回までのPython道場の記事はご覧いただけたでしょうか?
前回は、商品と店ごとの売上の予測というKaggle内の課題を通して、データ分析の流れをご紹介しました。
まだご覧になっていないという方は、ぜひご覧ください!
2013年1月~2015年10月の商品と店ごとの毎日の売上から、2015年11月の商品と店ごとの売上を予測する記事
今回は番外編ということで、前回の順位やスコアを上げることで、データ分析の精度を上げるまでの流れをご紹介します。
データの分析は一回やって終わり、というわけではなく、精度を上げるために何度も何度も行う必要があります。
一個一個の項目を見るだけでは分からなくても、項目の組み合わせによって何らかの関係や法則が見いだせる…なんてこともあります。
ビッグデータやAIを活用した売上向上や効率化、コスト削減に興味のある方は、ぜひ前回の記事も含めて最後まで読んでみてください!
それでは見ていきましょう。
この記事の目次
前回分析したデータ
まずは前回分析したデータを改めてざっと見てみます。
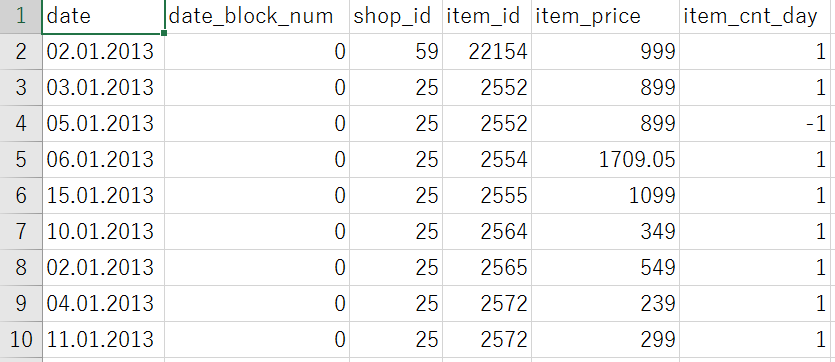
こちらは、分析対象である、2013年1月~2015年10月の商品と店ごとの毎日の売上の一部でした。
左から順に、
日付、年月を表す番号(2013年1月なら0、2013年2月なら1…2015年10月なら33)、店ごとのID、商品ごとのID、商品の販売価格、その日に売れた商品の個数
を表しています。
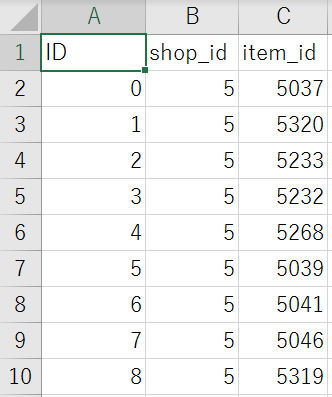
こちらが予測対象のデータの一部でした。
左から順に、
ID(行番号)、店ごとのID、商品ごとのID
を表しています。
与えられた、店ごとのIDと商品ごとのIDに対する2015年11月の売上を予測することが目標でした。
分析データの整理
分析精度を上げるためには、まず極端な値のデータやありえない値のデータを取り除いたり、何か別の値で補完したりする必要があります。
多くの場合、元のデータはAIにとって分析しやすいものではなかったり、間違った方向に学習したりしてしまうものです。
例えば分析対象のデータの4行目には…
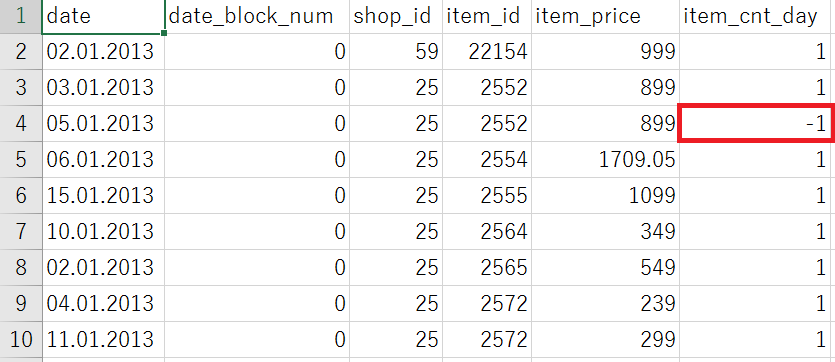
item_cnt_day、つまり、その日に売れた商品の個数が-1個となっています。
このようなデータがありえない値をとるデータであり、削除したり別の値に変えたりする必要があるデータです。
同様に、

item_price、つまり、商品の販売価格が0未満のデータもありえない値をとるデータです。
今回はこれらのデータは削除しました。
他にも、以下のようなデータを削除しました。
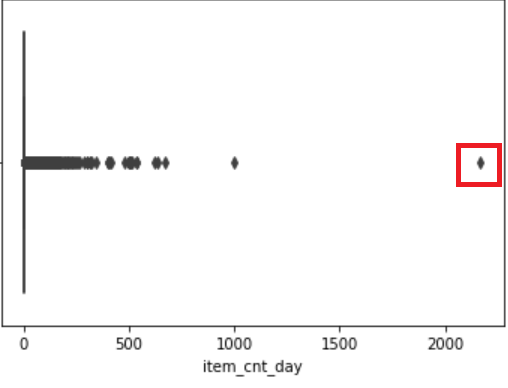
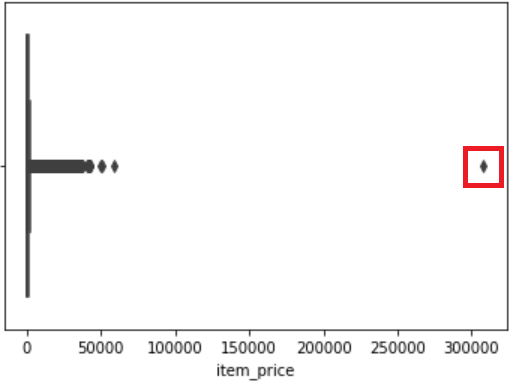
上の2枚の画像はそれぞれ、その日に売れた商品の個数と商品の販売価格のデータがどう集まっているかを表す図です。
どちらも左側に近づくにつれ、点が集まって太い線のようになっています。
一方、右側に近づくにつれ、点の間隔がまばらになっています。
極端な値のデータとは、それぞれの画像で赤枠で囲んだような、明らかに他のデータとは異なる値をとるデータのことです。
このような値を削除することで、データの傾向をより掴むことができます。
分析データを多角的に視る
データの整理をした後に、様々な角度からデータを視て分析します。
今回は分析データに次のような特徴を見つけることができました。
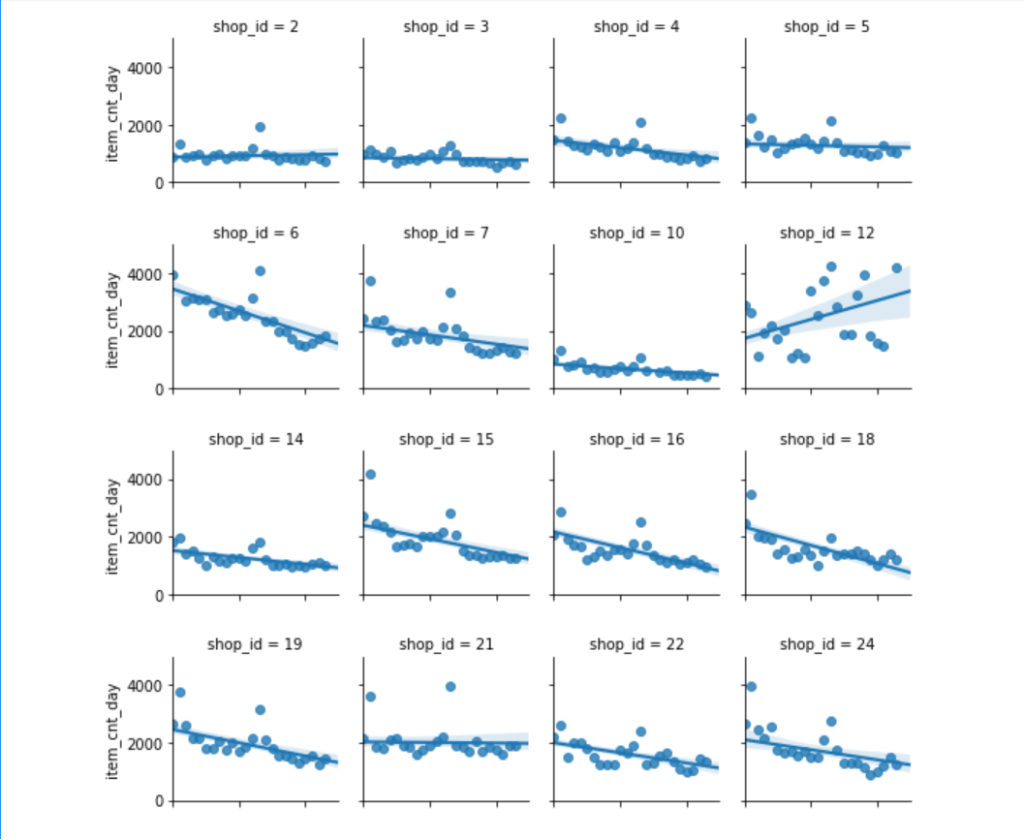
上の画像は、各店ごとの月別の全商品の販売総数を表すグラフの一部です。
横軸がdate_block_num(年月を表す番号)、縦軸がitem_cnt_day(その日に売れた商品の個数)を表しています。
何となく、各グラフに描かれている直線のあたりにデータが集まっているような気がしませんか?
今回はこのグラフを参考に売上を予測しました。
このデータを前回と同じ、重回帰分析でAIに学習させました。
その後、予測対象データの店ごとの商品数で、分析した各店ごとの月別の全商品の販売総数を割ることで予測しました。
今回の結果は…

2021年6月28日時点で、8192位/12841人でした。
ちなみに、右側の1.21756というスコアが正解との誤差を表しており、0に近づくほど分析が正確であることが分かります。
前回のスコアが5.38962だったので、かなり躍進しました!
まとめ
いかがでしたか?
今回は、データ分析の精度を上げるまでの流れの一例をご紹介しました。
ビッグデータを分析することのイメージが少しでも鮮明になったでしょうか。
ビッグデータをAIに学習させて高い予測精度を出せるようになると、なぜそう言えるのか?ということが明確に分かります。
そのため、経験則よりも正確な判断をすることができ、売上向上、コスト削減といったことがより達成しやすくなると考えられます。
とても夢のある話だと思いませんか?
今後も様々なデータを分析して、数多くの分野のデータで予測精度の高い分析ができるように挑戦していく予定です。